CPP学习笔记(1)
《C++ Primer Plus》读书笔记(1)
学校发的C++教材是那本比较经典的《C++大学基础教程(第五版)》,对于我来说内容太少了,所以C++课我都不看那本书,自己刷《C++ Primer Plus(第六版)》(下文简称CPP)。不得不说有一定基础来读这本书真的很舒服,更加详悉全面的讲了很多东西,收获颇多。这个是一个系列,在这更新一点看到的新东西和比较难理解的地方,以及在看书过程中查到的资料等,也算是定期复习。
虽然有覆盖页码这个说法,但是也不是每次都能写完,万一有就下次补充了~
覆盖页码:1~339
1. cin返回值
cin是一个对象,但是在输入的时候存在一个bool类型的返回值来表示文件是否到达末尾。也就是说:
| |
其实是等价的。在很多时候处理输入就会比较方便。
2.传参效率
众所周知,C++存在三种传参方式。
| |
它们之间的区别各种书都会讲,这里主要谈引用传参和拷贝传参的效率问题。从编译实现上来说,引用传参一般效率比较高,但是很多时候我们只是需要传入值去计算而不是修改原值,那么我们怎么做?很简单:
| |
原理是这样的,根据作用原理,第一个函数实现必须要在内部创建临时变量存储a和b的值,这部分内存和时间开销根本没有必要,所以我们选择了第二种实现,直接把变量传进去,同时使用了const限定符,保证内部不会修改a和b,减少部分开销,实际上提升了效率。
3.using指令问题
using指令两种用法:
| |
二者存在这样的区别:
编译器预处理指令跟
#define之类一样,直接导入整个命名空间,那么对于下列代码:1 2 3 4using namespace std; //此时已经导入了cin ifstream cin("xxx.xxx");那么
cin会局部变量隐藏全局变量,只有我们定义的cin起了作用。using声明则大有不同,看这个:1 2 3 4using std::cin; //using声明也导入cin ifstream cin("xxx.xxx"); //编译器报错!为什么报错呢?
using声明实际上声明了cin,也就是引用了std这个命名空间里面的cin定义,然而这个时候我们想自己定义cin的时候就出现了单一定义冲突,编译器肯定报错。
从刚才的讨论其实导出一点,就是我们更多时候应该使用using声明或者直接上作用域解析运算符来使用命名空间的变量,而不是一股脑导入。不过做ACM题之类的还是无伤大雅的:)
4. 模板函数
模板是泛型的内容,像我这样喜欢重复造轮子的人十分喜欢这种概念。
这个部分主要讨论匹配问题:
首先考虑如下代码:
| |
这个相信大家都能看懂,下面讨论的所有代码上方都有如上定义。
实例化
实例化就是把一个模板函数实例成为一个对应数据类型的函数的过程。这里有两种形式,隐式和显式。
看如下例子:
1 2 3 4 5 6 7 8 9 10 11 12int a,b; float c,d; //case 1 swap(a, b); //case 2 swap(c, d); //case 3 swap<int>(a, b); //case 4, but may not work. swap<int>(c, d); template void swap<int>(int, int);很简单的,case 1和2都是隐式实例化,当编译器翻译到这一行的时候,就会知道根据传参类型自动生成一个
int类型的max函数给case1,生成一个float类型的max函数给case2。而case3和case4都是显式的,这么指定就要求编译器对这两组数据都生成一个int类型的max函数,如大家所知道的,对于case4会出现截断问题,而对于case3就能完美工作。最后一行那个代码也是显式实例化,但是我们很少这么用。我们用到显式实例化的地方一般是写了一个类,比如自写List的时候:
1 2 3 4 5 6 7template<typename T> class List{ T *head; ... }; ... List<int> myList;那这个时候我们使用类的时候,显式指定成员变量类型为
int的一个链表myList,就能执行对int的基本操作。具体化
具体化就是指定一种数据类型下模板函数该怎么做的过程。这个过程必须显式。
看如下例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14class Dorm{ std::string name; int roomNumer; int bedNumber; }; //declaration template <> void swap<Dorm>(Dorm &, Dorm &); //defination template <> void swap<Dorm>(Dorm &stu1, Dorm &stu2){ swap(stu1.roomNumber, stu2.roomNumber); swap(stu1.bedNumber, stu2.bedNumber); }可以看到,显式具体化需要有函数声明和函数定义,因为具体化,我们必须具体指出函数行为,实际上就是同名函数的一个重载过程。
上面实现了一个简单的宿舍类,记录了学生姓名,房间号和床号。当我们交换两个学生床位的时候,我们不能直接使用已定义好的模板函数
swap,因为这样会交换二者的名字。这样我们必须显式指出面对Dorm类成员的时候,swap函数应有的行为,这个时候我们就使用显示具体化。那么为什么我们需要这样做呢?我们不是有重载吗?实际上,这里我也没有详细考证。根据函数匹配来看,使用重载函数的优先级显然高于一个显式具体化的模板函数;而从代码风格来看,给出重载函数也比显式具体模板函数看起来更清晰易懂。所以我个人推荐是对于特殊的情况使用函数重载而不要使用使用显式具体化后的模板函数。(如果有特例未来会更新)。
5.编译器函数匹配问题
这个问题是一个大坑,所以我尽可能简单说。
一般来说,编译器拿到你的代码,会遇到这样的代码:
| |
好了,编译器遇到这么多函数,当你调用的时候,它怎么选择合适的函数去匹配呢?
首先要明确的一点是,假如有两个最适匹配,也就是两种匹配都能做到最简单,那么编译器就会报错。这个很好理解,这两种匹配下面的实现可能有不同,也可能相同,调用可能会带来很严重的副作用,编译器不能冒这个险,所以下面谈优先级都是建立在不会出现两个或以上函数出现同级最适匹配的情况。
那么我们简单来说,编译器遇到匹配的时候,是这样的步骤:
- 创建候选函数列表。
- 使用候选列表创建可行列表。
- 查找是否有最适匹配。
从内部来看,创建可行列表的时候编译器还会做隐式类型转换,比如说有一个double的模板,那么明显可以考虑作为float参数的可行函数,因为存在float到double的隐式转换。
我们重点讨论第三个,援引CPP289页的一个例子:
| |
从上面来看,may函数被重载了7次,其中#6和#7还是参数模板重载。
首先看第一步,编译器会直接排除#4和#7,因为传参类型转换过程中不存在整数或者字符变量转换为指针变量的转换(注意,字符变量和字符串数组的区别),这两个就不存在,那么现在剩下5个。
第二步,生成可行列表之后要找最适匹配,一般来说,以下四条的优先级依次递减:
- 完全匹配,常规函数。
- 完全匹配,模板函数。
- 提升转换,如
float到double,short转换为int。 - 标准转换,如
char转换为int。 - 用户定义转换,比如类声明中定义的。
从这里来看,上述函数的优先级就能这么排序:#3和#5>#6>#1>#2。
很明显,这里匹配重复了,编译器必定报错。
最适匹配存在着例外情况。下面只探讨两例:
无关紧要的类型转换
下面这个表描述了无关紧要的类型转换。
实参 形参 TypeType &Type &TypeType []* TypeType (args)Type (*) (args)Typeconst TypeTypevolatile TypeType *const Type *Type *volatile Type *那么也就是说,遇到这个表的时候,会进行这么转换,转换的同时不会影响具体性。
具体性
当编译器去匹配两个函数的时候,会看怎么样的匹配更具体。比如看这个例子:
1 2 3 4 5 6 7 8 9//两个模板调用 //模板签名 template<class Type> void recycle(Type t); //显式具体化 template <> void recycle<bolt>(bolt & t); //调用 bolt a; recycle(a);在这种情况下,显式具体化明显比模板更具体,因为它显式指定了要进行的操作。
再看此例:
1 2 3 4 5 6 7 8//两个模板调用(2) //模板签名 template<class T> void recycle(T t); template<class T> void recycle(T* t); //调用 int a; recycle(&a);会调用哪个?第一个。很简单,当编译器匹配的时候,第一个里面将把
T换为int *,这样只需要一次转换。那么有人会问,第二个直接把T换成了int不也是一次转换吗?但是我们要这么看,当编译器在匹配第一个的时候,只用前后T都转换就行,而第二个要检测到参数类型为T*的时候才能知道前面的T应该转换为int,第一个明显更加“无脑”,所以自然第一个转换更少,更具体。最后看这个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15//两个函数模板 template <class T> void ShowArray(T arr[], int n); template <class T> void ShowArray(T * arr[], int n); //调用 double k[3]={1.1, 2.2, 3.3}; double *pd[3]; for(int i = 0; i < 3; i++){ pd[i]=&k[i]; } ShowArray(pd, 3);ShowArray调用的时候会匹配哪一个?第二个。很明显的是,第二个完整的指出了要匹配的参数类型为T * arr[],和pd完全匹配,更具体。那么实际上第一个也可以匹配,直接把T解释成double *就行,但是明显第二个具体程度强于一。
这个坑就写到这里,感觉可能有些错误,之后有机会再详细谈谈。
6.C++11表达式值类型
C++11前的标准对于一个表达式只有两种类型,左值(lvalue)和右值(rvalue),而在C++11更新后(尤其是右值引用的加入后),标准上把原有的两种类型拓展到了五种。下面讲讲区别。
首先上图:
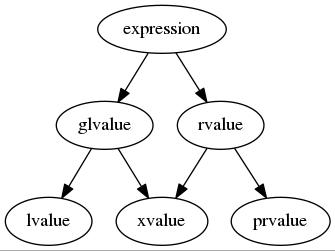
下面分开介绍:
最基本类型:
左值(lvalue)
左值其实很简单,是一个变量或者函数名。这里要注意下面这几种情况也是左值:
- 内建赋值、复合赋值、前置自增、前置自减表达式,如
a+=b、--a。 - 左值引用返回值的表达式,如上面的
getline函数。 - 内建逗号表达式,如
a, b,其中b是左值。 - 字符串字面量,如
"Hello, World!"(很好理解,C++内部把字符串还是按C风格存储,即const char *[]类型)。
- 内建赋值、复合赋值、前置自增、前置自减表达式,如
纯右值(prvalue)
纯右值的出现完全是因为C++11新增的右值引用而出现的,实际上就是把之前的右值概念搬了一下,大部分都是右值。右值引用之后再谈。要注意下面几种情况也是纯右值:
- 除字符串之外的字面量。如
42、nullptr。 - 内建的后置自增、后置自减表达式。如
a++。 - 内建的取地址运算符。如
&str。 - 内建逗号表达式,如
a, b,其中b是右值。 this指针。- lambda表达式。
- 除字符串之外的字面量。如
亡值(xvalue)
这个东西就有点炫酷了,这个是C++11引入的新类型。命名来源是“eXpiring",从名字就能知道,亡值就是说即将到作用域终点,从而可以被自动内存管理下回收利用的值。这个值只会是自动内存管理的产物,不会是手动申请的堆内存的产物。
以下的表达式为亡值:
返回对象为对象的右值引用的函数或者重载运算符,比如
std::move(x)。a[n],内建的下标表达式,操作数之一是数组右值。这个要看下标运算符重载。内建的下标运算符是这么一个重载:
1 2T& operator[](T*, std::ptrdiff_t); T& operator[](std::ptrdiff_t, T*);看到重载知道这是一个引用返回,当操作数是数组右值的时候就返回亡值引用。
a.m,对象成员表达式,其中a是右值且m是非引用类型的非静态数据成员。a.*mp,对象的成员指针表达式,其中a为右值且mp为指向数据成员的指针。a ? b : c,对于某些a、b和c的三元条件表达式。转换为对象的右值引用类型的强制转换表达式,例如
static_cast<char&&>(x)。这个从显式实例化就知道,这个转成了一个右值引用,所以必返回亡值。
混合类型:
泛左值(glvalue)
泛左值要么是左值要么是亡值,可以通过转换隐式转换变成纯右值,包括左值到右值、数组到指针或者函数到指针的转换。
右值(rvalue)
右值要么是亡值要么是纯右值。很明显的,所有右值都不允许取地址运算,也不能作为任何内建的赋值或者复合赋值运算符的左操作数。
注意事项:
- 左值可以被取地址,但是亡值不行。也就是说,不是泛左值都能被取地址。
这部分现在只能写这么多,未来理解更深了可能会提出来再写。
第一次先写这么多吧,写着写着自己都惊讶怎么这么多了。但是其实还有很多没写,比如作用域链接性之类的问题,这些坑下次再填吧,我也写不动了。
没有Markdown要我用Word排版这个样子发篇博客我还不如跳楼。
C++ is powerful, coding is fun!